Co-written with Ahmed Riaz ⇒
Originally published on UXmatters.com August 3, 2009 ⇒
When the Web began, pages were mostly text, but today, everywhere we look, it seems like image content is taking over the Web. The ubiquitous use of digital cameras and improvements in the picture quality of mobile phone cameras has likely helped this phenomenon along. The shift toward content that is primarily visual introduces new challenges and opportunities for developing intuitive and powerful user interfaces for browsing, searching, and filtering visual content. To help me cover this important topic, I’ve asked Ahmed Riaz—Interaction Designer at eBay and physical interaction design enthusiast—to contribute his insights and ideas.
Introducing Visual Browsing
What, you may ask, is visual browsing? Loosely defined, visual browsing user interfaces are those that let people navigate visual content—that is, search for content using pictures. We will discuss four types of visual browsing:
- browsing images or photos using text attributes or tags—for example, on Google Images and Flickr
- using images in queries to describe attributes that are hard to describe with text—as on Like.com and Zappos
- using images to facilitate wayfinding and navigation in the real world—such as on Google Maps and Photosynth
- collecting and browsing images on mobile devices—like on RedLaser and NeoReader
Each of these approaches to visual browsing supports different goals for searchers and introduces its own unique challenges, design directions, and best practices, which we’ll explore next.
Browsing Images Using Text Attributes or Tags
While there are many image-centric sites, the majority of the Web’s image content is on either Google Images or Flickr. No discussion of visual browsing would be complete without mentioning these two sites. When it comes to finding images that are published somewhere on the Web, Google Images is the site most people go to. Google uses a proprietary algorithm to assign keywords describing each image, then index and rank all of the images in their enormous database. They also capture a thumbnail of each image and store it along with the source URL.
While Google Images is undeniably a very useful site, it exemplifies some of the challenges of automated image finding. The primary mechanism for finding images is a text-only query, which perfectly demonstrates the impedance mismatch that exists between text and image content. Because no single keyword can adequately describe all of the pixels that make up an image—and, most of the time, the keywords that surround an image on a page provide an incomplete description at best—Google Images interprets search queries very loosely. Typically, it interprets multiple keywords using an OR instead of the usual and expected AND operator. As a consequence, it omits some keywords from the query without letting the searcher know explicitly what is happening.
On the one hand, because Google Images interprets search queries in a such a loose fashion, it rarely returns zero search results. On the other hand, image searches sometimes give us strange and unpredictable results, while making it challenging to understand what went wrong with our queries and how to adjust them to find the images we’re really looking for. Figure 1 shows an example—the search results for Africa Thailand elbow Indian.
Figure 1—Google Images search results for Africa Thailand elbow Indian
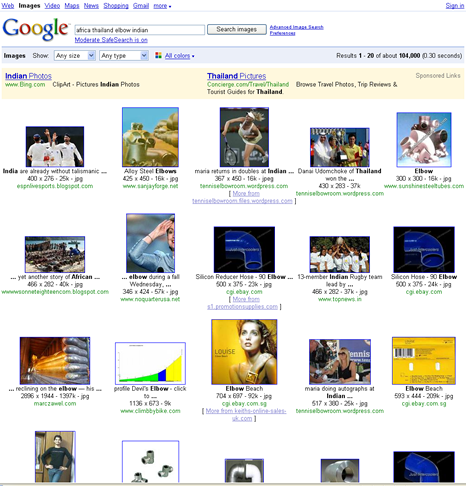
Judging from the search results, Google Images seems to have omitted keywords randomly from the query, without indicating to the searcher it has done so. Of course, one could argue that getting such poor results for a query is an example of garbage in/garbage out. However, we think this example demonstrates that the keywords Google takes from the surrounding content on a Web page—and possibly some Web pages that link to it—do not always match an image. While an image may technically be located at the intersection of Africa, Thailand, elbow, and Indian, this by no means guarantees that the image would actually show Indian warriors demonstrating the perfect Mai Thai elbow-strike technique on the plains of the Serengeti.
Plus, a computer-generated index usually makes no distinction between the different possible meanings of an image’s surrounding keywords—for example, a search engine can’t tell when an image appears in juxtaposition to text to add humor. Nor do automated indexing engines handle images well when they have purposes other than providing content—such as images that add visual appeal or bling or those for marketing or advertising. Such image content is, at best, orthogonal to its surrounding text.
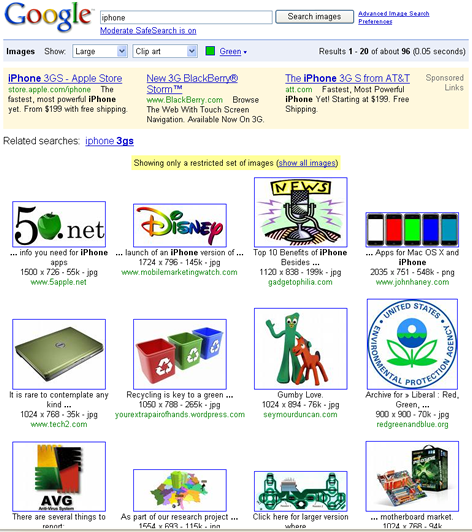
Image search filters that are based on text are, at the moment, not particularly robust. For example, Figure 2 shows Google Images search results for iPhone with some filters applied. As you can see, the resulting images have little to do with the iPhone.
Figure 2—Google Images filtered search results for iPhone
As a photo-hosting site, Flickr enjoys the distinct advantage of having people rather than computers look at, interpret, and tag the images they create and view. Users can search for images by their tags. While Flickr is not a perfect image-searching system, it provides an entirely subjective, human-driven method of interpreting and describing images. Why is that valuable?
According to Jung’s conception of the collective unconscious, we can assume all individuals experience the same universal, archetypal patterns. These archetypes influence our innate psychic predispositions and aptitudes, as well as our basic patterns of human behavior and responses to life experience. Likewise, at the root of all folksonomies is the inherent assumption that people—when we look at them collectively—tend to respond in similar ways when presented with the same stimuli. Simply put, people looking for images of cats would be quite happy to find the images that a multitude of other people have taken the time to tag with the word cat.
As Gene Smith describes in his book, Tagging: People-Powered Metadata for the Social Web, folksonomies and tagging usually work quite well—in most cases, nicely resolving the kinds of issues that occur in Google Images due to auto-indexing, which we described earlier. Unfortunately, the human element also introduces its own quirks along the way. Take a look at the example of a Flickr image shown in Figure 3.
Figure 3—One of the most interesting Flicker images tagged with iPhone
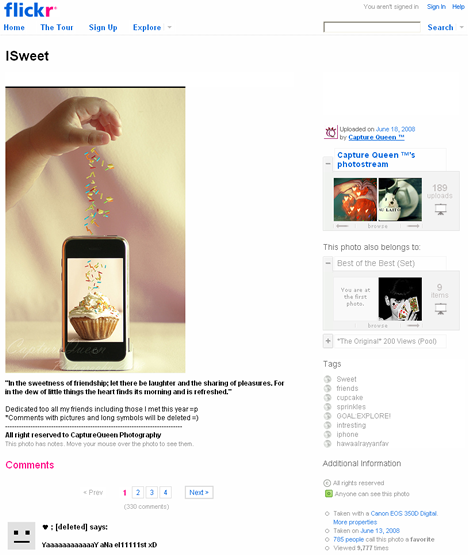
Among almost 2 million Flickr images tagged iPhone, Flickr considers this image one of the most interesting, with 785 favorites and 37 comments. As you can see at the bottom of the page, one of the problems with having a community-driven popularity algorithm is that some people post nonsense comments just to be able to say they’ve added a comment to a popular item.
Another problem has to do with tags that are strictly personal. For example, tags like GOAL:EXPLORE! and hawaalrayyanfav have meaning only to the person who actually tagged the item—and little or nothing to the population at large. On the other hand, adding tags like funny and humor is actually quite useful, because computers don’t recognize humor at all. In fact, humor is the aspect of image description where algorithm-based search results fail most spectacularly. We’ll talk more about folksonomies, controlled vocabularies, and searching for tags in future columns. For now, we’ll just say that neither way of finding images—through text tags or associated surrounding text—is perfect, and there is a great deal of room for improvement, perhaps through combining both search approaches, using a single algorithm and a user interface that does not yet exist.
Using Images in Queries
We think one of the most intriguing aspects of visual browsing user interfaces has to do with the mismatch between images and the text algorithms or people use to describe them. They highlight the inherent limitations of finding and managing images through text-based queries. Typically, a person sees an object, determines what to call it, then tries a few keyword searches based on that interpretation. Adding a photo to a query lets a searcher bypass the interpretation step and just let the computer see what the query is about.
On the Web, one of the more successful examples of image-based search is the shopping site Like.com, which lets searchers use images as part of their queries to describe the attributes of items that are difficult, if not impossible, to describe precisely using text alone.
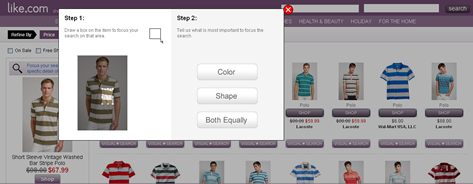
While Like.com has some issues when it comes to presenting good entry points into their enormous inventory for people who like to browse, once you find an item you’re interested in, the search engine is absolutely phenomenal at picking up visually similar items. For example, Figure 4 shows the results for an image-based search that is based on a picture of a striped shirt. The algorithm is smart enough to explore useful and popular degrees of freedom, deviating from the starting image, while keeping the zeitgeist of the original image intact.
Figure 4—Like.com image-based search results

In addition to doing a great job of exploring the possible degrees of freedom from the original image, the system lets shoppers fine-tune their queries to match a specific part of an image by zooming in on the part they’re interested in. This is very similar to selecting part of an image on Flicker and tagging only that part of the image. For example, a user could tag a person in an image as friend and a snake in the image as giant anaconda, while naming the entire image The last-known picture of Billy—hopefully adding the tag humor, while he is at it. As images become more ubiquitous on the Web—and generate evermore layers of meaning—being able to select and annotate only part of an image will become more and more important in a visual browsing user interface.
The Like.com search algorithm can relax different attributes, including color, pattern, and shape, as well combine image searching with text attributes, demonstrating the potential of image-based searching and browsing.
While government sources can neither confirm nor deny this, the Department of Homeland Security is allegedly interested in image-based search technologies, mainly in regard to facial recognition. However, as Munjal Shah, CEO and Cofounder of Riya told the audience at the MIT/Stanford Venture Lab’s Next Generation Search Symposium in 2007, commercial-grade facial recognition technology is not quite there yet. Such search algorithms can generally recognize which part of an image is a human face and venture a fairly accurate guess at a person’s gender, but recognizing a specific face requires matching the precise expression and angle of the face in a photograph with the sample, which can often be difficult. Despite these limitations, the potential of image-based search technology is enormous.
Does a user interface need to have a true visual-search algorithm to perform image-based search? Although technology helps, it does not afford the only way of performing a visual browse. One alternative is to have a human being tag items, using abstract visual attributes—such as a range of icons or outlines of shapes, using limited screen real estate—that, in turn, would let customers describe their visual queries. This kind of a pseudo-image-based search could, for example, successfully complement the existing people who shopped for X, also shopped for Y metrics-based algorithm.
Using Images for Navigating in the Real World
By now, most people are familiar with street view in Google Maps, which is pictured in Figure 5.
Figure 5—Google Maps street view
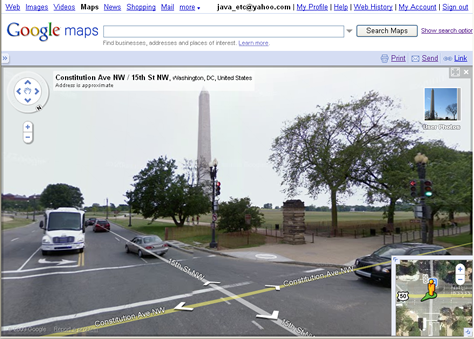
Using this phenomenal technology is almost like being there, with virtual-reality controls for navigating through nearly continuous photos of real space. Google Maps is an excellent example of automated sense-making of images, using precise GPS coordinates. Visual browsing controls let users walk, turn around, and jump through real space, using virtual projection. However, as anyone who has looked up their street and their house can tell you, these pictures are frozen in time. Some people can even tell you when the Google Maps picture of their house was taken, because a friend’s car was captured in the satellite photo.
In contrast—or perhaps as a complement to Google Maps—Photosynth, Microsoft’s new acquisition, uses crowd-sourced photographs to construct and let users navigate through 3D street-level space. It can also add the fourth dimension of navigating through time, letting users cross-reference multiple images. The feel of the interaction evokes looking into vignettes and being able to shift your point of view through space and time. One of the best examples available of this new capability is the Photosynth of the Obama inauguration![]() .
.
What is really interesting about this emerging technology is that it sidesteps—quite literally—the issue of a finite density of information within a single photograph. With systems like this, we are moving into a world where—rather than relying on just keywords and tags—we can use deep image analysis to sort and restructure sets of images and make sense of what we are looking at. The computer can truly see a real 3D space.
Collecting and Browsing Images on Mobile Devices
Using images as input for searches on a hand-held device is reminiscent of using barcode readers to enter inventory counts into a computer. Historically, barcode recognition required the use of a specialized device that was available only to governments and larger businesses. However, recent developments in mobile technology are rapidly changing this paradigm. An increasing number of mobile phone applications like RedLaser, LifeScan, and NeoReader, which is shown in Figure 7, now let customers snap photos of barcodes, using their mobile phones, then immediately use the photos as input for a search algorithm.
Figure 7—NeoReader iPhone application
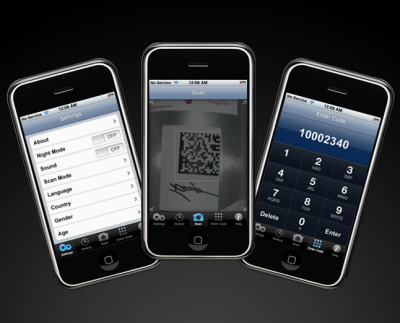
Another tool called Semapedia offers an interesting way of using mobile barcode recognition. Semapedia makes it possible to tag any item in the physical world with a barcode that contains a link to the appropriate Wikipedia Web page. A person can use a mobile phone with the free NeoReader application to read the link’s URL and navigate to the Web page providing Wikipedia content about the object or place a person is looking at. http://www.merkwelt.com/people/stan/semapedia_offline/
Another example of the capability of mobile barcode-recognition technology comes from the Suntory Company in Japan, which tagged their beer cans with a special 2D barcode. Scanning this barcode with the application NeoReader takes a consumer to a mobile Web site that lets visitors register to offset 100g of CO2 emissions once per day and get tips on mitigating their own greenhouse gas emissions.
Both of these examples demonstrate that we are moving ever faster toward a world that is populated by smart objects, which Bruce Sterling dubbed spimes. We can track spimes’ history of use and interact with them through the mesh of real and virtual worlds that pervasive RFID and GPS tracking create. Mobile picture search is certainly emerging as the input device of choice for connecting the real and the virtual worlds to create the Internet of Objects.
Peter Morville, in his book Ambient Findability, talks about the sensory overload, trust issues, and bad decisions that are sure to result from our interactions with the Internet of Objects. However, it is hard to elude the siren’s call of such technology. It is now almost possible to use technology similar to that of Like.com to analyze every image and frame of video a mobile phone captures and tag them with text, GPS coordinates, time, and author. At the same time, it is possible to cross-reference each image with other images of the same place or similar things, along with all the tags, content, and links an entire world of users has added to this collection of images. The technology to collect all of these images in a massive 3D collage that users can navigate along a time axis, Photosynth-style, is also just around the corner.
Interactions of this kind make it possible to establish a unique and natural connection between the real world and the Internet computing cloud. The key is the added meaning the computer provides, based on its understanding and interpretation of the content of an image. Imagine, for example, taking a picture of a CD cover with your mobile phone’s camera and sharing it with your friends to learn what they think about the music; using the same picture to get more information about the artist on the Web—for example, pictures, videos of recent concerts, and a biography; finding out where you can buy the CD at the best price online; or using GPS to find coupons to purchase the CD from a local merchant. Imagine being able to do all of this with only a few screen taps and without typing a single character, while listening to a sampling of the CD’s tracks, playing through headphones connected to your mobile phone.
We are just starting to scratch the surface of these types of massively distributed, image-based, human-to-mobile interactions. Although image-processing speeds are getting much better—witness the smooth, fast scrolling of iPhone photo album images versus the slow shuffle of images on a Treo—the time it takes to process images on a mobile device and send them back and forth between that device and a server is still the biggest barrier to this type of technology. Once the image feedback loop is nearly instantaneous, this new paradigm for mobile input will truly come into its own, bringing the digital world ever closer to the real world and ushering in the arrival of a brave new world of visual browsing.

P.S. Like what you are reading? Go VIP.

Join 6,000+ subscribers getting exclusive content, Q&As, book giveaways, and more. No spam. Just design that works.
References
Jung, Carl Gustav. Man and His Symbols. New York: Dell, 1968.
Morville, Peter. Ambient Findability. Sebastopol, California: O’Reilly, 2005.
Nudelman, Greg. “Making $10,000 a Pixel: Optimizing Thumbnail Images in Search Results.†UXmatters, May 11, 2009. Retrieved July 26, 2009.
Riflet, Guillaume. “Semapedia, or How to Link the Real World to Wikipedia.â€![]() Webtop Mania, August 26, 2008. Retrieved July 26, 2009.
Webtop Mania, August 26, 2008. Retrieved July 26, 2009.
Smith, Gene. Tagging: People-Powered Metadata for the Social Web. Berkeley: Peachpit Press, 2008.
Smolski, Roger. “Beer, Carbon Offset, and a QR Code Campaign.â€![]() 2d code, July 27, 2009. Retrieved July 26, 2009.
2d code, July 27, 2009. Retrieved July 26, 2009.
Sterling, Bruce. Shaping Things. Cambridge, Massachusetts: MIT Press, 2005.
 The Mystery of Filtering by Sorting
The Mystery of Filtering by Sorting